每天给你送来NLP技术干货!
来自:FundanNLP
Motivation
在实体关系抽取中,前人在编码任务特征上大致上可以划分为两类:序列编码(Sequential Encoding)和平行编码(Parallel Encoding)。
序列编码一般按先NER再RE的先后顺序对任务特征进行编码,这种编码方式会使得后编码的特征无法直接影响到先编码的特征,从而导致不平衡的任务间交互。
平行编码则是使用两个独立的编码器来生成任务特征,这种编码方式除了共享输入外就再无其他交互方式, 这会导致不充分的任务间交互。

论文链接:https://arxiv.org/pdf/2108.12202.pdf
代码链接:https://github.com/Coopercoppers/PFN
主要工作
本文提出了新的编码范式-联合编码(Joint Encoding),并基于该范式设计出一种适配多任务学习的编码器 – 分区过滤编码器(Partition Filter Encoder)。
该编码器能够同时编码NER和RE的任务特征来保证充分平衡的任务间交互,从而有效规避序列编码和平行编码带来的不足。文章的主要贡献如下:
提出一种基于联合编码的分区过滤网络。
模型在6个数据集上取得了SoTA,超过了TpLinker、Table-Sequence、PURE等多个联合/流水线抽取SoTA模型。
探讨了RE对NER的作用,通过辅助实验得出:RE对NER具有显著的促进作用。该结论佐证了联合抽取的必要性以及其相较于流水线抽取的优越性。
模型结构
模型主要划分为两个模块:分区过滤编码器(Partition Filter Encoder)和解码单元(NER Unit and RE Unit)。解码部分使用了常见的填表方法(Table Filling)。
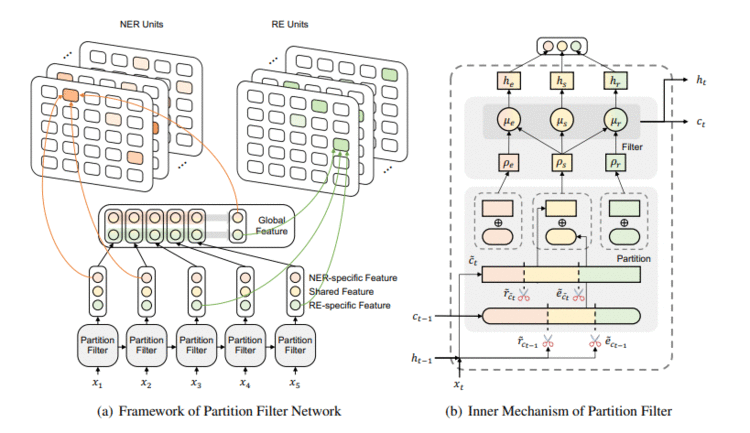
编码部分
编码器采用了类似LSTM的自回归形式。对每个时刻,编码过程被划分成了两步:分区(Partition)和过滤(Filter)。分区指的是将神经元划分为三个独立区域:一个共享区(Shared Partition)和两个任务独享区(实体区和关系区),过滤则是将这些分区进行组合,去掉与任务无关的分区。
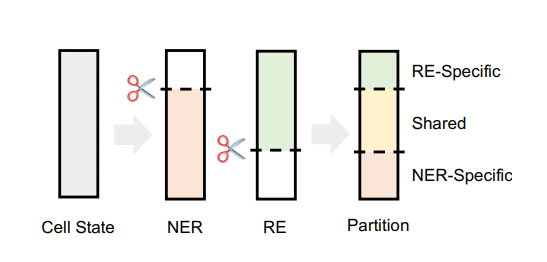
分区
模型使用了实体门e和关系门r来对神经元进行分区。这里神经元指的是类似LSTM中的cell单元。
首先根据对NER/RE的有用程度,实体门/关系门会把cell划分成两个区域,一个与任务相关,一个与任务无关。如上图所示,根据NER和RE的划分结果,我们最后得到了三个分区,中间的共享区(Shared)表示对NER和RE都有用的信息,两端的任务独享区表示只与单个任务有关的信息。
实体门e和关系门r的计算采用了cummax激活函数,输入为当前时刻的输入xt以及上一时刻的隐状态ht-1:
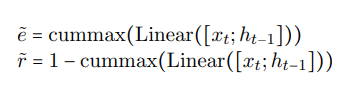
cummax的计算包括两步:
第一步是对每个神经元进行Softmax()操作,这一步用来确定分区的割点。
第二步计算每个神经元的累加值,即cumsum,得到了近似(0, 0, 1, 1, 1)的二元门(binary gate)。0的部分表示割点之前的神经元,1的部分表示割点之后的神经元。
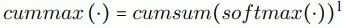
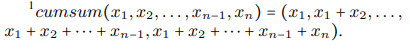
为了加深理解,举个简单的例子。
假设cell单元有5个神经元,对输入Softmax()后通常会使某个神经元(即割点)的值变得相对较大。假设softmax后值为(0.1, 0.1, 0.6, 0.1, 0.1),在这里割点就是第3个神经元。此时对该序列做cumsum后得到的结果是(0.1, 0.2, 0.8, 0.9, 1.0)。这一结果近似可以看做是划分成两个区域的二元门(0, 0, 1, 1, 1)。
有了实体门e和关系门r之后,三个分区就能够计算出来了:
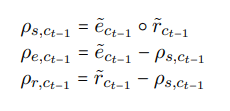
这里用一个例子来说明上式的逻辑,假设e =(0,1,1),r =(1,1,0)。
公式第1行里对实体门和关系门按元素相乘得到了共享区ρs为(0, 1, 0),即共享信息来自第2个神经元。
公式第2-3行用实体门或者关系门减去共享区得到了任务独享区ρe. ρr分别为(0, 0, 1)和(1, 0, 0),这说明NER和RE的独占信息分别来自第1,3个神经元。
其中公式下标后面的ct-1表示分区的对象是t-1时刻的cell单元。
文章里对两类cell单元分别进行了分区操作,一类是代表历史信息的ct-1,另一类是代表当前信息的ct。最后把两类cell的分区信息加起来,得到了总的分区信息:
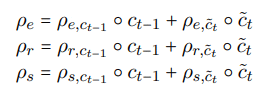
过滤
过滤阶段需要对三个分区进行组合过滤,组合过滤的原则是使NER和RE能够平等地获得共享区信息,同时让NER和RE分别专享实体区和关系区信息,这样可以在保证均衡交互的同时剔除掉与任务无关的信息。最后组合的信息分别存储在三个记忆单元中(实体记忆µe,关系记忆µr以及共享记忆µs):
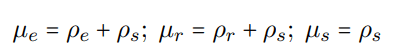
最后对记忆单元进行简单的非线性处理即可得到最后需要的任务特征:
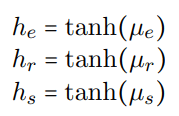
由于模型采用了自回归编码的方式,最后还需要产生下一时刻的cell state和hidden state:
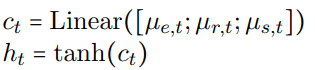
另外作者还提出使用句子级别的全局特征来作为解码的补充信息:
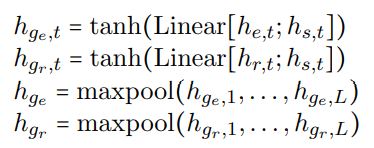
解码部分
模型在解码的时候把NER和RE分成了两个独立的部分。对句子中的每对单词,作者将词级别的任务特征和句子级别的全局特征进行拼接,把多分类问题转化成多个二分类问题来进行类别预测(NER里是实体类别,RE里是关系类别):
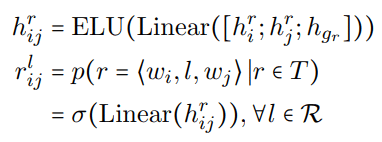
NER(wi, wj)在NER中分别表示实体的首尾词,在RE中分别表示Subject实体和Object实体的起始词。损失函数使用的是二分类损失函数BCEloss。
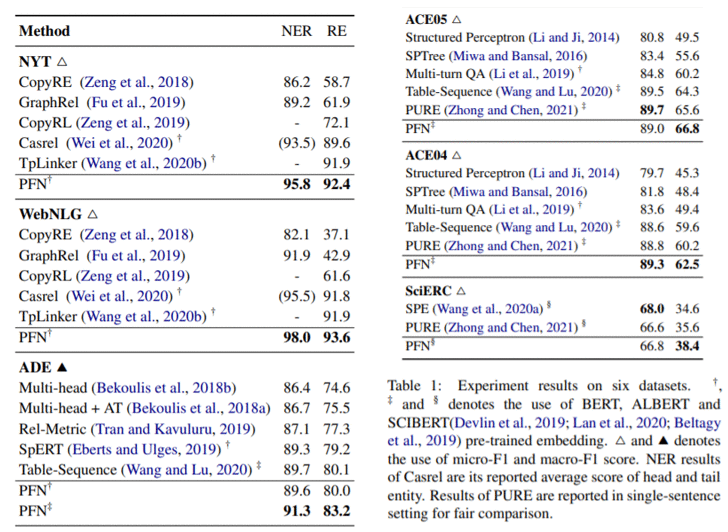
主实验
作者在6个数据集上做了实验,可以看到模型的表现很好,在性能上超过了Tplinker、Table-Sequence和PURE等多个SoTA模型。
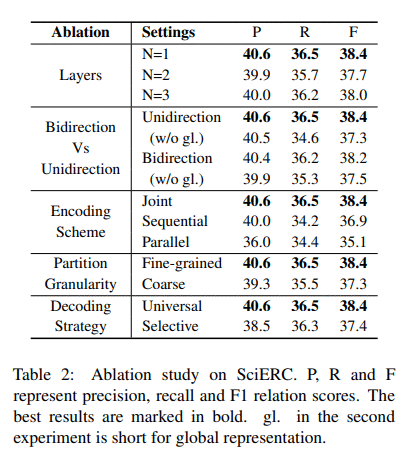
消融实验
作者对编码器的层数、方向、编码方式、分区细粒度以及解码方式上都做了消融实验,从结果来看,新提出的联合编码相较于序列编码和平行编码有着不小的提升。
探讨RE对NER的影响
众所周知,NER是RE的上游任务,对RE的具有非常大的促进作用。但是RE是否也会在一定程度上影响NER?这一影响是否大到非做联合抽取不可的程度?前人在这一问题上讨论的很少。
此前对这一问题进行过分析的有“A Frustratingly Easy Approach for Entity and Relation Extraction”。这篇论文提出了流水线抽取模型PURE,并得出RE对NER预测没多大用处的结论。
在本文中,作者对该结论以及即支撑实验提出了质疑,并通过实验得出了与PURE截然相反的结论:RE对NER具有显著的积极影响。
首先作者按照实体是否出现在三元组中将其划分为两类:in-triple和out-of-triple,并分别测试两组实体的抽取效果。
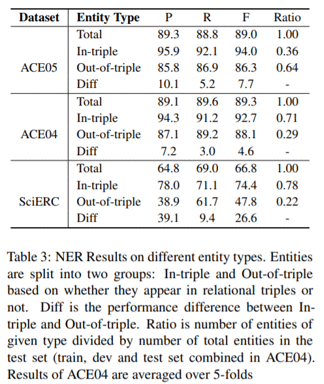
结果显示,NER预测中in-triple实体的F1值要显著高于out-of-triple。这说明预测未出现在三元组中(即不包含RE信息)的实体要更加得困难。
另外作者在NER上使用了鲁棒性测试来评估模型对输入扰动的鲁棒性,扰动方法用了复旦大学张奇老师组提出的TextFlint。
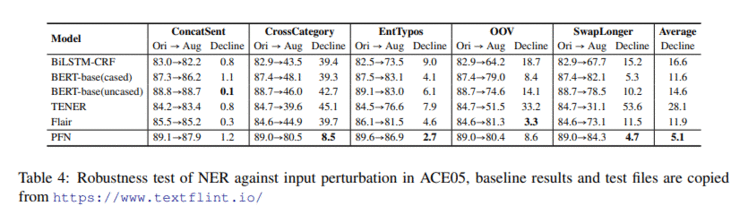
总体来说联合模型在输入扰动下性能下降的幅度要小于其他不引入RE信息的baseline,尤其是CrossCategory(该方法将实体随机替换成其他在多语境下可能存在不同实体类别的实体, 比如同时可作为地名和人名的Washington)。可以看到RE信息的引入让NER预测变得更加鲁棒。
由以上两个实验,作者得出RE对NER具有积极明显的促进作用。并且作者认为由于PURE采用了有偏的实验设置,其结论不具备可靠性。
有偏体现在两点:一是设置联合抽取baseline时对NER和RE使用了Share Encoder,这种方法会造成任务间的侵蚀作用:即对其中一个任务有用的信息,可能对另外一个任务来说是无关甚至有害的。二是采用了out-of-triple类实体占绝大多数比例的ACE05数据集来进行评估,而out-of-triple实体抽取本身并不需要RE信息。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!






 京公网安备 11010802041100号
京公网安备 11010802041100号